Most AI certifications test whether you know the product. The Claude Certified Architect exam tests whether you know when to use it differently.
I didn’t fully appreciate that until I started going through the material. It changes how you prepare.

I’ve been building out a study repo as I prep for the CCA-F. Most of what I’ve flagged as worth knowing isn’t about syntax or API surface area — it’s about judgment. Here’s what I’ve found.
The exam at a glance
60 multiple-choice questions. 120 minutes. Pass score 720/1000. $99 per attempt (the first 5,000 partner attempts were free at launch). It launched March 12, 2026 and is Level 301 — Anthropic expects you have at least 6 months of hands-on Claude experience before sitting it.
The format is scenario-based. Four of six scenarios are randomly selected on exam day, with roughly 15 questions each. You get dropped into a realistic production context — customer support automation, multi-agent research pipelines, CI/CD integration — and asked what you’d actually do.
Distractors aren’t obviously wrong. They’re subtly wrong in ways that only matter in production. That’s what makes it harder than it sounds on paper.
The 5 domains (and where the weight is)

Five domains, not equal weight. Agentic Architecture is 27% of the exam. If you’re short on time, start there.
Domain 1 — Agentic Architecture & Orchestration (27%) is about structuring multi-step, multi-agent systems. Not “what is an agent” — how coordinator agents pass context to subagents, how workflow prerequisites get enforced, how you read the agentic loop correctly. The concept that shows up in nearly every question here: stop_reason.
Coming from data engineering, a lot of this maps to pipeline thinking — task decomposition, dependency management, failure handling. The difference is the workers are probabilistic. A Spark job runs or throws an exception. An agent makes judgment calls, and that changes what you can actually guarantee at the orchestration layer.
Domain 2 — Tool Design & MCP Integration (18%) is about what makes a tool selectable in practice. Why giving an agent too many tools degrades reliability. How error responses need to be structured so an agent can actually recover rather than just retry the same failing call.
Domain 3 — Claude Code Config & Workflows (20%) covers the CLAUDE.md hierarchy, custom commands, path-specific rules, and CI/CD integration. The recurring question: where do shared standards live, and what breaks when they’re in the wrong place?
Domain 4 — Prompt Engineering & Structured Output (20%) is mostly precision. Explicit criteria beat vague instructions. tool_choice eliminates JSON syntax errors but doesn’t touch semantic ones. The validation-retry loop — and knowing when to stop.
Domain 5 — Context Management & Reliability (15%) is the “lost in the middle” problem, escalation triggers, and how you handle conflicting information across sources without the model just picking one arbitrarily.
Five concepts that kept coming up
These showed up across every domain. Each is a question where both options look defensible, and the wrong pick only reveals itself in production.
1. stop_reason, not text parsing
The agentic loop rule: stop_reason == "tool_use" means keep going, stop_reason == "end_turn" means exit. Never parse the response text to detect completion.
The instinct most developers have is to scan for phrases like “I’m done” or “Task complete” in the response. Text output is probabilistic. stop_reason is a structured field. The exam tests this one directly.
2. Programmatic gates vs prompt instructions
This shows up in almost every domain. Financial operations, security checks, compliance rules need programmatic enforcement — 100% compliance. Prompt instructions run at roughly 95-98%. That gap matters when you’re processing a payment or writing to a production database.
The exam frames it as: which approach for X? Money, data integrity, irreversible actions — programmatic. Style guidelines — prompt instructions are fine.
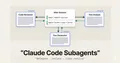
3. Context isolation in multi-agent systems
Subagents don’t inherit their coordinator’s context. Sounds obvious until you see it in a scenario: coordinator has gathered state mid-session, question asks what the subagent knows. Answer: only what was explicitly passed to it.
I covered this more in the Claude Code subagents post. Isolation is what makes subagents clean and cheap to run — it’s also the assumption that breaks most first attempts at multi-agent systems.
4. Tool descriptions are the primary selection mechanism
When a tool gets misrouted or ignored, the fix is improving the description. Not adding examples, not reordering the list, not writing routing logic around it.
A good description tells the model when to use the tool, when not to (explicit “do NOT use for X” boundaries), what the input format looks like with a real example, and at least one edge case. Vague descriptions are why tools get skipped.
5. Escalation triggers
Right triggers: customer explicitly asks for a human, no policy covers the situation, agent can’t make progress after N attempts.
Wrong triggers: sentiment score below a threshold, self-reported low confidence, customer used aggressive language.
Frustration and complexity aren’t the same thing. The exam offers sentiment-based escalation as a distractor — reject it.
Before you prep: Anthropic Academy prerequisites
Anthropic runs a free learning platform at anthropic.skilljar.com with 17 self-paced courses. No subscription, no credit card — just an email.
These are the ones that map directly to exam domains:
| Course | What it covers | Exam domain |
|---|---|---|
| Claude Code 101 | CLAUDE.md, Plan Mode, subagents, skills, MCP, hooks | Domain 3 |
| Introduction to Subagents | Subagent config, context isolation, orchestration | Domain 1 |
| Introduction to Agent Skills | Skills setup, SKILL.md format, invocation | Domain 3 |
| Claude Code in Action | Tool use, context management, GitHub workflows | Domains 2 & 5 |
| Introduction to MCP | MCP servers, client integration | Domain 2 |
| Claude 101 | Core features, prompting, best practices | Domain 4 |
How I’m structuring prep
My study repo is organized by domain with working code for each concept. The scenario implementations are the most useful part — they mix multiple domains in realistic production contexts, which is closer to how the actual exam reads than notes alone.
The sample questions (with explanations) are what I’d prioritize. Same format as the real exam, including the distractors. Understanding why each wrong answer fails is more useful than drilling the right ones.
Other resources I’ve actually used:
- The official Anthropic docs for Claude Code and the Agent SDK — not everything is on the exam, but context helps with edge cases
- Tutorials Dojo CCA-F study guide for a different angle on domain coverage
- My earlier posts on Claude Code subagents and Agent Skills — both map directly to Domains 1 and 2
The prep order that makes sense
Start with Domain 1 (agentic architecture, 27%), then Domains 3 and 4 (Claude Code config and prompt engineering, 20% each), then Domain 2 (tool design, 18%), then Domain 5 (context management, 15%).
Aim for 900+ on practice exams before booking. The pass score is 720, but scenario-based questions are harder to hit 720 on than isolated recall. Build in margin.
Read the scenario setup before the questions. Most wrong answers are technically correct in isolation — the scenario is what makes one of them right.
Study repo: traviteja-git/claude-certified-architect-foundations — all 5 domains with hands-on exercises, scenario implementations, sample questions, and a cheatsheet.
If you’re preparing for the CCA-F or have already sat it, I’d love to hear what you found hardest. Reach out on LinkedIn — happy to compare notes.